データ型の変換
フォームを含み、Webアプリケーションの受け取るクエリのデータはすべて文字列です。数字を入力するフィールドであっても、Pythonで受け取るデータは文字列となります。
Pythonは、Perlなどと比べ型の扱いが厳密です。そのため、Webアプリケーションで扱うデータは明示的に型の変換を行う必要があります。
たとえば、数字のみで構成された文字列型のテータと数値型で足し算をしようとするとエラーになります。インタラクティブシェルを使って試してみましょう。
:::python
>>> "123"+456
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot concatenate 'str' and 'int' objects
Pythonでは、演算をする前に型を揃えてやる必要があります。数字だけで構成される文字列を整数に変換するには、組み込み関数の「int()」を使います。文字列として連結したい場合には、組み込み関数の「str()」を使います。
:::python
>>> int("123")+456 579
>>> "123"+str(456) 123456
勝手に変換される方が便利、という考え方があるかもしれませんが、それはPythonの思想に反します。あいまいさをできるだけ排除する、というのがPythonの思想なのです。数値を文字列として扱って連結するのか、または文字列を数値として扱って足し算するのか、型を揃えることで明確に処理の内容を指示し、誰が読んでも分かりやすいプログラムを書く、というのがPythonの思想なのです。
Webアプリケーションに送られてくるほとんどのデータは文字列です。Pythonはデータの型を厳密に扱う傾向にあります。このため、処理の内容によっては型の変換を行う必要があります。
フォームのどの部品にどの値が入力されたかを知るには、コントロールのnameを使います。クエリを取り出し処理を行うときに、nameを指定してデータを取り出し、扱うデータの性質によって文字列型から変換を行うわけです。
データの変換で最もよく使われるのは文字列型から数値型への変換です。Pythonの数値型には、整数型と浮動小数点型があり、変換の方法も別になります。
文字列型から整数型への変換を行う
組み込み関数のint()を使います。引数として数字、符号のみを含む文字列を与えると、数値型が戻り値として返ってきます。int()には、小数点や数字以外の文字を含まない文字列を与える必要があります。数字以外の文字列をint()に与えるとエラー(ValueError)が発生します。
文字列型から浮動小数点型への変換を行う
組み込み関数のfloat()を使います。引数として数字、符号、小数点を含む文字列を与えると、浮動小数点型のデータが返ってきます。int()と同じく、英字など余計な文字列を含む文字列を与えるとエラー(ValueError)が発生します。
数値型に変換できるかどうかを調べる
int()、float()とも、変換の妨げになるアルファベットのような文字を含む文字列を引数として与えるとエラーが発生します。そのため、処理を行う前に文字列の内容を確認する必要があります。このような処理を「文字種の検 査」と呼ぶことがあります。
文字種の検査は正規表現などを使っても可能です。しかし、文字列が数値のみで構成されているかどうかを調べたい場合には、文字列メソッドのisdigit()を使うと便利です。このメソッドは、文字列が数字のみで構成されている場合に真(True)を返します。
:::python
>>> "1234".isdigit() True
>>> "123F".isdigit() False
isdigit()は整数であることを検査するためには便利です。しかし、プラス、マイナスなどの符号、小数点が含まれていても偽(False)が返ってきます。このため、浮動小数点などを含む数値の検査には利用できません。
符号を含んだ文字列、浮動小数点に変換する文字列を検査する場合には、別の方法を使うことになります。正規表現を使った方法も1つのアイデアですが、ここでは「例外(エラー)」を使って、スマートに型のチェックを行う方法について検討してみましょう。与えられた数値によって、適切な型のデータを作って返す関数を作ってみます。文字列にアルファベットなどが交じっていて変換できなかった場合はゼロを返します。
:::python
def toNumber(num_str):
"""文字列を適切な型の数値に変換する"""
try:
value=float(num_str)
if value==int(value):
return int(value)
except ValueError:
return 0
まず、関数をtry〜exceptで囲みます。この中で起こった例外(エラー)のうち、ValueErrorのみを捕まえます。例外が起こったときにはゼロを返します。引数の文字列に、変換の妨げになる文字列が混じっていた場合、float()関数を呼んだときに例外が発生します。
その後、int()関数を使って再度変換を試みています。文字列に浮動小数点が含まれていないときには、整数を返すわけです。
ユニコード型への変換
WebアプリケーションのUIから、クエリとして送られてくるデータは文字列です。日本語のようなマルチバイト文字列は、特定エンコードの8ビット文字列となって送られてきます。Pythonで日本語のようなマルチバイト文字列を扱う場合には、ユニコード文字列を使うのがなにかと便利です。このため、日本語のようなマルチバイト文字列が含まれる可能性のあるクエリを処理する場合は、8ビット文字列をユニコードに変換することになります。
実際にどのような手法を使ってユニコード型への変換を行うかを説明する前に、簡単にエンコードについて解説したいと思います。
コンピュータで扱う文字には、すべて番号が振られています。どの文字にどの番号を振るか、という取り決めのことをエンコード(符号化方式)と呼んでいます。アルファベットや数字、よく利用する記号などを含んだASCII文字には、共通したエンコードがあります。
しかし、日本語や中国語、韓国語などアジア圏の国々では、複数のエンコードが存在します。同じ「あ」という文字をコンピュータで表現するために、複数の数字が割り当てられている、ということです。コンピュータ上に日本語のようなマルチバイト文字を表示するとき、エンコード方式を間違えると正しい文字列が表示されません。一般的に言われる「文字化け」はこのように起こります。
フォームなどから送られてくるクエリをユニコード文字列に変換するためには、このエンコードの情報が必要です。ユニコード文字列に変換を行う関数にエンコード名を文字列として与えることで、正しくエンコードの変換が行えます。
特殊なケースを除いて、フォームから送信される文字列のエンコードは、フォームなどを表示しているWebページのエンコードと同じと思ってほぼ間違いありません。フォームのHTML自体のエンコードはあらかじめ分かっていることが多いわけですから、特別な場合を除いてエンコードの変換に困ることはないでしょう。
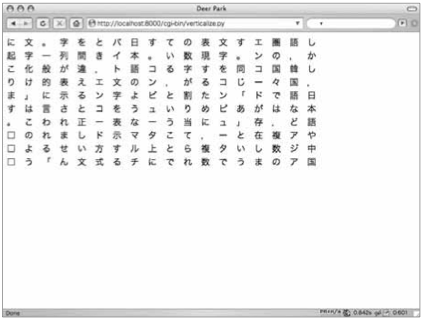
縦書き変換プログラム
ここで、マルチバイト文字列を扱う簡単なWebアプリケーションを作ってみることにしましょう。フォームに入力された文字列を縦書きに変換して表示するプログラムを作ります。改行なし、いわゆる全角文字列のみを想定しています。また、カギ括弧や区点などの記号類を縦書き用に変換しない、という簡易なものを作ります。
文字列を縦書きにするためには、文字を1字ずつ分割して並べ替えを行わなければなりません。Pythonの8ビット文字列では、マルチバイト文字の区切りを識別するために特別な処理が必要です。ユニコード文字列に変換すれば、文字の区切りを正しく扱うことができます。
まずはUIとなるフォーム(verticalize_form.html)を設置します。場所はドキュメントルート(PythonのWebサーバを設置したフォルダ)と同じ位置です。
List05 verticalize_form.html
:::html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
</head>
<body>
<form action="/cgi-bin/verticalize.py" method="POST">
<textarea name="body" cols="40" rows="20"></textarea>
<br />
<input type="submit" name="submit" />
</form>
</body>
</html>
その後、cgi-binフォルダにPythonのプログラム(verticalize.py)を設置します。実行権限を与えて、プログラムとして動くように設定してください。ファイルの設置が終わったら、PythonのWebサーバを起動して「~/verticalize_form.html」というURLにアクセスします。いわゆる全角文字、改行を含まない文字列を入力し、ボタンを押すと縦書きに変換されて表示します。
List06 verticalize.py
:::python
#!/usr/bin/env python
# coding: utf-8
import cgi
form=cgi.FieldStorage()
html_body = u"""
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8"> </head>
<body>
%s
</body>
</html>"""
body_line=[]
body=form.getvalue('body', '')
body=unicode(body, 'utf-8', 'ignore') # (1)
for cnt in range(0, len(body), 10):
line=body[:10]
line+=''.join([u'□' for i in range(len(line), 10)]) # (2)
body_line.append(line)
body=body[10:]
body_line_v=[u' '.join(reversed(x)) for x in zip(*body_line)] # (3)
print "Content-type: text/html¥n"
print (html_body % '<br />'.join(body_line_v)).encode('utf-8')
このプログラムでは、文字列を「リストのリスト」と見なし、右に90度回転することで縦書きの文章を得る、という方針で処理を進めます。リストのリストに分割する過程で、マルチバイト文字の区切りを正しく判定する必要があります。そのために、プログラムの中ほどでクエリを取り出し、unicode()関数を使ってユニコード文字列に変換しています(1)。
その後のループでは、文字列を10文字ごとに分割して文字列のリストを作っています。10文字より短い行があった場合には、埋め草(□)を使って文字列の長さを揃えています(2)。
ループの後が、文字列のリストを右90度に回転している部分です。一番のキモは、組み込み関数zip()を使った部分です(3)。組み込み関数zip()は引数として複数のシーケンスをとり、シーケンスの組み替えを行います。たとえば3×3の多次元配列のようなシーケンスをzip()にかけると、シーケンスの回転(実際には写像)を行うことができます。以下の例が分かりやすいで しょう。なお、この例では改行を調整しています。
:::python
>>> zip((1, 2, 3),
(4, 5, 6),
(7, 8, 9))
[(1, 4, 7),
(2, 5, 8),
(3, 6, 9)]
この性質を使うと、横書きを縦書きに変換することができます。日本語の縦書き文章は右から左に読み進めます。zip()で得た変換後のシーケンスをリスト内包表記で再度展開し、組み込み関数reversed()で左右を反転しています。
図04 縦書き変換Webアプリケーション