
Webアプリケーションと データの保存
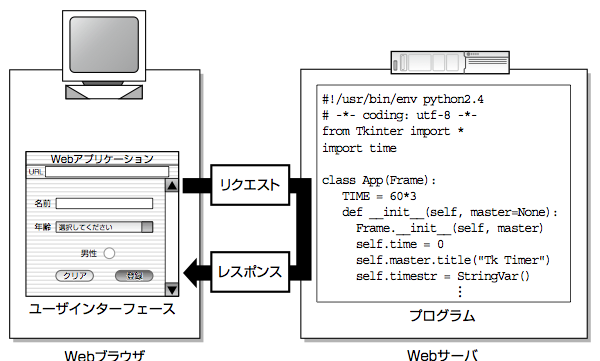
本書の最初では、Webアプリケーションの基本的な動作原理について解説 をしました。クライアントとサーバの間で、リクエストとレスポンスを繰り返して処理を続けていくというのが、Webアプリケーションの基本的な動作の流れです。
実際にリクエストやレスポンスとしてやりとりされるデータは、形式を持ったテキストデータであるということについても学びました。データの受け渡しは、HTTPという通信手順(プロトコル)に従って行われます。表面的に見えるデータ以外にも、たくさんの情報がヘッダという形でやりとりされています。
Webアプリケーションとセッション
Webブラウザがリクエストを送り、リクエストを受け取ったWebサーバがレスポンスを返す。Webの処理の基本となるこの一連の流れをセッションと呼びます。Webアプリケーションの処理は、このセッションを1つの単位として進んでいくことになります。
Webアプリケーションに指示を与えるためにはリクエストを使います。たとえば、Webブラウザ上に表示したフォームに文字列などを入力して、リクエストをPOSTします。すると、フォームに入力したデータがリクエストに乗ってWebサーバに送られます。Webサーバ上のプログラムで、リクエストに乗ったデータを解析して、処理を行います。処理の結果は、レスポンスとしてWebブラウザに戻っていきます。
Webブラウザから送られたデータは、ネットワーク通信の上に乗って送られています。通信はたいてい一瞬で終わり、Webサーバがリクエストを受け取った後には消えてしまいます。同じ内容のデータを送信するためには、フォームに同じ内容を再度記入するなどして、同じ内容のデータを送信する必要があります。POSTリクエストでなく、GETリクエストを使えば、URLにリクエストの内容が残ります。何度も同じ内容を送信するのならGETリクエストを使えばよいわけですが、リクエストを再度送信する必要がある、という点では同じことです。
図01 リクエストとして送られた情報はすぐに消えてしまう
また、Webアプリケーションでは、多くの場合リクエストを受け取ったときにプログラムが動き出します。レスポンスを送信した後は、プログラムは終了します。プログラム自体が終了しますので、プログラムの内部で保存していた変数やオブジェクトは消えてしまいます。後で利用したいデータは、どこかに保存しておかなければならないのです。
このように、リクエストとして送ったデータや、Webアプリケーション内部で作成したデータは、特別な処理をしないと消えてしまいます。Webのデータ通信の仕組みには、基本的にデータを保存するための方法がありません。一般的なWebアプリケーションでは、過去にリクエストとして受け取った情報を再利用したい場面がよくあります。過去に投稿したブログの記事をフォームで再編集する、またはWebアプリケーションの個人用設定を保存しておく。このような処理を実現するためには、Webサーバの側でデータを保存する必要があるのです。
標準ライブラリを使ってデータを保存する - pickleを使う
PythonのWebアプリケーションで、リクエストとして受け取ったデータを保存するにはどうすればよいでしょうか。プログラムで受け取ったデータを消えないように残し、後で再利用できるようにするには、ファイルにデータを保存すれば良さそうです。リクエストとして受け取ったデータをファイルに書き出し、必要に応じて読み込んで再現する、という処理をするわけです。
データの保存とシリアライズ
プログラムのデータをファイルに書き出すとき、必ず考えなければならない問題があります。ファイルというのは一種の巻きもののようなものです。必ず前から後ろに向かって読み進めていきます。
文字を順番に並べた文字列のようなデータであれば、ファイルにそのまま保存をして、元の状態を再現することができます。しかし、Pythonのリストや辞書など、構造を持ったデータの場合はそうはいきません。構造を持ったデータをファイルに書き出すためには、一度前から後ろに読めるように変換を行う必要があります。このような処理のことをシリアライズと呼んでいます。
たとえば、リストをファイルに書き出すことを考えましょう。ファイルに書き込むのは文字列のような一次元のデータです。リストをいったん文字列に変換し、必要に応じて復元する方法を考えます。次のような処理をするとします。
リストをファイルに書き出す
リストの要素を、カンマ(,)のような区切り文字を使ってファイルに書き 出す。
ファイルからリストを取り出す
ファイルから文字列を読み込み、カンマで区切った文字列を分割する。
たとえば、文字列だけで構成されたリストであれば、この方法でリストのシリアライズと復元が行えます。ただし、リストの文字列にカンマが含まれていると、区切りがおかしくなってしまいます。また、文字列以外のデータ、たとえば数値や辞書などを要素として持つ場合は正しく処理が行われないはずです。
文字列だけでなく、数値がリストの要素にあったらどうなるでしょうか。または辞書のような複雑な構造を持つデータを要素に持つリストを完全にシリアライズするためには、複雑なプログラムを書かなければなりません。いずれにしても、簡易な方法では扱えるデータの種類に制限ができてしまいます。
標準モジュールpickleを使ってシリアライズを行う
データをファイルに保存するこためには、前段階としてシリアライズをする必要があります。いろいろな種類のデータを、過不足なくシリアライズする処理を作るのは,実は意外と大変なのです。自分自信で,完璧なシリアライズを行うプログラムを作ろうと思うと,とても手間がかかってしまいます。
Pythonの標準モジュールには、組み込み型を含むいろいろなデータをシリアライズするpickleというモジュールが備わっています。ここでは、piclkeを使ってPythonのデータをファイルに保存する方法を検討してみましょう。
pickleを使うと、Pythonのいろいろなデータを文字列に変換することができます。また、変換した文字列を元に、元のデータを復元することができます。Webアプリケーションで保存したいデータを一度文字列にすることで、ファイルに保存しやすくなります。また、ファイルに保存した文字列をpickleモジュールの関数を使って処理することで、元のオブジェクトを復元することができます。
pickleモジュールには、大まかに分けて2種類の関数があります。文字列をベースとして、Pythonのオブジェクトをシリアライズ、復元する関数と、ファイルをベースに処理を行う関数です。
dumps(obj)、dump(obj、 file)
Pythonのオブジェクトを引数に渡し、シリアライズを行う関数です。 dumps()は、シリアライズした結果を文字列として返します。dump()は、ファイルオブジェクトを引数に添え、シリアライズした結果をファイルに書き出します。
loads(string)、load(file)
dumps()、dump()でシリアライズした文字列から、Pythonのオブジェクトを復元する関数です。loads()は、Pythonのオブジェクトをシリアライズした文字列を引数として渡します。load()はシリアライズした結果を書き出したファイルを引数として渡し、Pythonのオブジェクトを復元します。
インタラクティブシェルを使って、実際にシリアライズと復元の過程を試してみましょう。まず、数値と文字列を要素に含むリストを定義します。その後、dumps()関数を使ってオブジェクトをシリアライズした文字列を取り出しています。最後に、オブジェクトをシリアライズした文字列から元のリストを復元しています。pickleを使うと、リストだけでなく、辞書やリストのリスト、クラスといった複雑なオブジェクトをシリアライズできます。
シリアライズと復元
:::python
>>> import pickle
>>> l=[1, 2, "three", "four"] >>> ps=pickle.dumps(l)
>>> print ps
(lp0
I1
aI2
aS'three'
p1
aS'four'
p2
a.
>>> pl=pickle.loads(ps)
>>> print pl
[1, 2, 'three', 'four']
Webアプリケーションでデータを保存する
では実際に、データを保存するWebアプリケーションを書いてみましょう。好きな軽量言語について投票し、投票結果を表示するWebアプリケーションを書いてみます。RSSリーダーと一緒に作った、リクエストとレスポンスをスマートに扱うためのクラスを活用してみましょう。
図02 好きな言語の投票を行い、結果を保存するWebアプリケーション
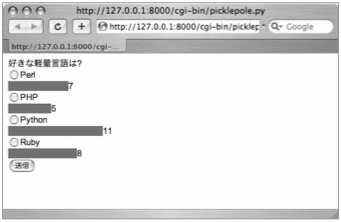
このWebアプリケーションでは、簡略化のため、投票用のフォームと、投票結果は1つのプログラムで表示するようにします。投票用のUIとしてはラジオボタンを使います。投票結果は、CSSを活用して棒グラフとして表示します。プログラムでは、投票用のフォームと投票結果の棒グラフを表示するHTMLを動的に生成し、表示するわけです。
プログラムの内部では、投票をした結果は、言語の名前をキーにしたPythonの辞書オブジェクトとして扱います。フォームで投票を受けると、選択された言語の名前に相当するキーの値として保存されている数値に1を足します。その後、辞書オブジェクトをpickleモジュールを使いシリアライズして文字列に変換し、ファイルに保存します。保存したファイルに書かれた文字列を、pickleモジュールを使って再度辞書オブジェクトに変換すれば、直前に投票した内容を再利用できます。
以下のプログラムが、投票を行い、結果をファイルに保存するWebアプリケーションです。先ほど作成したhttpdhandler.pyというモジュールをおなじディレクトリに置いた状態で使います。
picklepole.py
:::python
#!/usr/bin/env python
# coding: utf-8
import pickle
from httphandler import Request, Response, get_htmltemplate
import cgitb; cgitb.enable()
form_body=u"""
<form method="POST" action="/cgi-bin/picklepole.py">
好きな軽量言語は?<br />
%s
<input type="submit" />
</form>"""
radio_parts=u"""
<input type="radio" name="language" value="%s" />%s
<div style="border-left: solid %sem red; ">%s</div>
"""
lang_dic={} # (1)
try:
f=open('./favorite_langage.dat')
lang_dic=pickle.load(f)
except IOError:
pass
content=""
req=Request()
if req.form.has_key('language'):
lang=req.form['language'].value
lang_dic[lang]=lang_dic.get(lang, 0)+1
f=open('./favorite_langage.dat', 'w') # (2)
pickle.dump(lang_dic, f)
for lang in ['Perl', 'PHP', 'Python', 'Ruby']: # (3)
num=lang_dic.get(lang, 0)
content+=radio_parts%(lang, lang, num, num)

res=Response()
body=form_body%content
res.set_body(get_htmltemplate()%body)
print res
プログラムの前半はモジュールのインポート、および表示に利用するHTMLのテンプレート文字列を定義している部分です。その後、投票結果を保存するため、lang_dicという変数に辞書オブジェクトを代入しています(1)。もし、前回投票時に保存したファイルがあれば、pickleモジュールを使って前回の投票内容を復元します。その後、Requestクラスのインスタンスオブジェクトを生成して、クエリから投票内容を取り出します。投票の内容によって、結果を保存するための辞書を更新します。辞書を更新したら、更新した辞書をpickleモジュールを使いシリアライズ、あとで利用できるように、文字列としてファイルに書き出します(2)。
最後はWebブラウザに表示するUIと結果の棒グラフをHTMLの文字列として組み立てています(3)。HTML文字列ができ上がったら、Responseクラスのインスタンスを生成して、レスポンスを作って返します。
これまでのサンプルでは、リクエストとして受けた情報をその場で処理してレスポンスとなるHTML文字列を組み立てていました。このプログラムでは、受け取った情報をシリアライズし、毎回ファイルに保存しています。Webアプリケーションでは、このようにデータの保存を行って初めて、データを再利用できるのです。
pickle利用とマルチスレッド
pickleを使うと、Pythonのオブジェクトそのものを文字列に変換し、時間をおいて元の状態を復元できます。アプリケーションでデータを保存したいときに利用すると便利なモジュールです。
ただし、Webアプリケーションでpickleモジュールを使いファイルにオブジェクトの内容を保存するときには、十分に注意する必要があります。
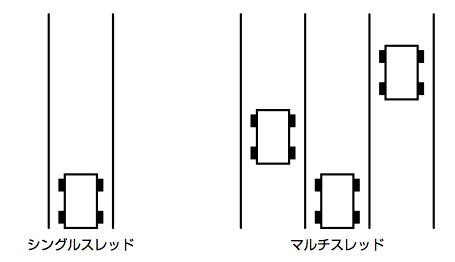
今使っているPythonのWebサーバでは、同時に1つのリクエストしか受け付けないようになっています。しかし、たいていのWebアプリケーションでは、同じプログラムが複数同時に動くようになっています。複数のリクエストを同時に受け付けることができるようになっているわけです。
Webアプリケーションが同時に動く様子を、道路の車線に例えてみると分かりやすいと思います。Webブラウザから送られるリクエストは道路の上を走る車と見なすことができます。車線が1つであれば、同時に1台の車しか通ることができません。多くの車が通ろうとすると、渋滞が起こってしまいます。多くの車をスムーズに通そうとするなら、車線を増やせばいいわけです。つまり、複数のWebアプリケーションが同時に動き、多くのリクエストを同時に処理できるようになれば、たくさんの仕事をこなすことができるようになるわけです。このように、1つのプログラムが同時に複数動くことをマルチスレッドで動くと呼ぶことがあります。
多くのWebアプリケーションでは、複数のプログラムが同時に動く
Webアプリケーションがマルチスレッドで動いているとき、pickleを使ってデータを保存するとします。Pythonのオブジェクトをシリアライズして文字列に変換し、ファイルに書き込むわけです。
並行して動いているプログラムが、同じファイルに読み書きをするとどのようなことが起こるでしょうか。
並行して動いているプログラムが、1つのファイルを読み込もうとするときは、問題は起きません。しかし、1つのファイルに複数のプログラムが同時に書き込みを行おうとすると、問題が起こることがあります。平行して動いているプログラムが同時に1つのファイルに書き込みをしようとするわけですから、部分的に書き込む内容が重複してしまったり、不正な文字列が書き込まれてしまうかもしれません。Pythonのオブジェクトをシリアライズした内容が正しく書き出されていないと、オブジェクトの復元も正しく行われません。オブジェクトが復元されなければ、プログラムは当然正しく動かなくなってしまいます。
このようなトラブルを避けるためには、1つのファイルに対して同時に書き込みが起こらないように、書き込みの処理をブロックする必要があります。同時書き込みをブロックするプログラムを書くのは意外と面倒で、また高度な知識が必要です。
そこで、たいていのWebアプリケーションでは、データを保存するために別の方法を活用します。それがデータベースです。多くのデータベースでは、同時に書き込みが起こってもデータが壊れないように設計されています。Webアプリケーションの側では、同時に書き込みが起こっているかどうかを気にすることなく、データを保存できるわけです。