
ソーシャルニュースサイトRedditのco-founder Steve Huffman さんが,月間2億7千万PVを誇るサービスを作る課程で学んだことを7つのレッスンにまとめてます。RedditはPython+PostgreSQL(リプリケーションはSlony)という構成で運用されていて,2億7千万ものPVを裁くために20以上のデータベースサーバを使っています。
RDBMSをKey/Valueのように使っているレッスン3のスキーマ設計の話などとても面白い。レッスンのいくつかはRDBMSバックエンドのシステムにのみ有効のようですが,たとえばレッスン6などはGoogle App Engineを使った非RDBMSバックエンドシステムにも効果がありそうです。
スライドの概略を伝えるエントリを超訳してみました:-)。ざくっと訳しちゃったので,細かい部分が間違っているかも知れません。ご指摘いただけると嬉しいです。
レッスン1 : クラッシュに備えよ
落ちたサービスは自動的に再起動するように作るべし。
自分のサービスを運用する場合,当然メンテナンスは時前で行う必要がある。たとえ午前2時にサービスが落ちても,すぐに復旧しなければならない。こういった状況は生活のすべての場面に入り込んできて,人生を台無しにする。
このような状況を避けるためには,落ちたり深刻な被害をもたらしうるプロセスを再起動するようにすればよい。Redditではsuperviceを使ってアプリを自動的に再起動している。アプリを監視するプログラムを作って,メモリやCPUを食い過ぎていたり,応答がなくなったプロセスをkillしている。再起動のログを読んで状況を把握すればよい。
レッスン2 : サービスを分割せよ
一つのサーバ(あるいは仮想マシン)にたくさんの仕事をさせようとすると,コンテクストスイッチングが頻繁に起こりパフォーマンス的に不利。それぞれのデータベースサーバに,単一の種類のデータを乗せるようにする。すると,インデックスのキャッシュイン/アウトが起こらなくなり,すべてキャッシュに載るようになる。似たようなデータは同じ場所に置く。Pythonのスレッドは,各スレッドが複数プロセスに配置されるので,遅いので使わないようにする。Pythonのスレッドを使わないと,プロセス間通信をする必要がなくなり,サービスを複数サーバに配置しやすくなる。設計がクリーンになるし,サービスが成長したときサーバを増やしやすくなる。
レッスン3 : オープンなスキーマを使え
サービスが育ってくるとスキーマのメンテナンスが大変になってくる。何百万もデータを持つテーブルにカラムを追加しようとするとロックが発生してうまくゆかない。そのあとリプリケーションサーバを再起動したり,アプリケーションとの整合性をチェックしたり,とにかく面倒なことが多い。
そのかわり,Redditでは二種類のThing(もの)とDataというテーブルだけを使っている。Reddit上のすべての「もの」は,ユーザ,リンク,コメントなどはThingテーブルに収まっている。Thingテーブルには投票結果や型,作成日といったデータを保存してある。Dataテーブルはid,key,valueの3つのコラムを持っている。title,url,authorといったThingに紐尽くすべてのアトリビュートについてDataのデータが作られる。新しいアトリビュートを追加する時は,テーブルを変更する必要はない。クエリでjoinは使わなくて良い。その代わり,一貫性は時前で保証する必要がある。joinがないということは,簡単にデータベースの冗長化が行えるということだ。外部キーや,どんな風にデータを分けるか心配する必要はない。
レッスン4 : 境界をなくせ
それぞれのサーバがすべての種類のリクエストを受け持つようにしておくのがよい。Redditでは,かつてサーバごとに別の役割を振っていた。これだとサーバが増えたときにキャッシュの効果がまちまちで,メモリの使用効率も悪い。その後,memcacheを使うようにアプリケーションを書き換え,サーバごとの機能差をなくした。そうすることで,サーバが落ちても他のサーバが機能を代替できるし,サーバを足せば簡単にスケールが増すようになる。
レッスン5 : memcacheを使え
全データにmemcacheを使え。
Redditではすべてにmemcacheを使っている。データベースのデータ,セッション,レンダリング済みのページ,関数の結果,ユーザの操作,ソート済みのリスト,ページ,ロックなどが具体例だ。今ではクエリの結果なども含め,PostgreSQLよりも多くのデータをmemcacheに保存して,高速なサービスを実現している。
Redditのページはすべてリストだ。フロントページ,インボックスやコメントページなどはリストだ。すべてのリストは事前に処理されていてキャッシュに保存されている。リストが必要な時はいつでもキャッシュが応答することになる。それぞれのコメントやリンクは,だいたい100種類ほどのソート順で保存されている。たとえば,2つ投票があるリンクは個別にキャッシュされる。30秒経つと再度レンダリングが行われる,といった具合。どんな小さなHTMLもキャッシュから配信されるので,CPUパワーがレンダリングのために無駄遣いされることはない。遅くなったら,単にキャッシュを追加すればよい。
データベースに不整合が発生したときは,memcacheをグローバルロックとして使う。最良の方法ではないかもしれないか,彼らはこの方法でうまくやっている。
レッスン6 : データを冗長化せよ
スピードへの鍵は,処理は事前に行っておき,結果をキャッシュすることだ。
遅いサービスを作る方法は至って簡単。完璧に正規化されたデータベースを作り,必要があるときに毎回クエリを投げ,ページをレンダリングする。リクエストごとに永遠とも思える時間がかかる。
高速なサービスを作るには,たとえばあるデータが複数のフォーマットで表示される場合には,それぞれのフォーマットで事前にデータを用意しておき,キャッシュすればいい。そうすれば,誰かがサイトを訪れてデータが欲しくなったとき,データはすでにそこにある,という状態を作り出すことができる。
Redditでは,リストは15種類のソート順を持っている(注目,新着,トップ,古いもの,今週のリスト,など)。だれかがリンクを登録すると,Redditでは変更の可能性があるリストを再度処理し直す。すこし無駄かもしれないし処理としては冗長かもしれないが,ユーザを待たせるより,ディスクやメモリに負荷を掛ける方がマシだ。
レッスン7 : オフラインで処理をせよ
バックエンドでの処理は最小に済ませ,長く掛かる処理はオフラインで処理して終わってからユーザに告知するようにする。
Redditでユーザが投票をすると,リストやユーザのカルマなどたくさんのものを更新することになる。ユーザが投票を行うと,データベースに投票が起こったことを知らせて,ジョブがキューに追加される。ジョブは20ほどの処理を実行する。ユーザが戻ってきたときには,更新がすべてキャッシュされている。
Redditが成長するにスレ「チート」に対するインセンティブが高まっている。Redditではチートを発見するために多大な労力を費やしているが,オフラインで処理が行われるため,サービスのパフォーマンスに影響を与えない。
以下はプレゼンテーションから拝借した構成図だ。
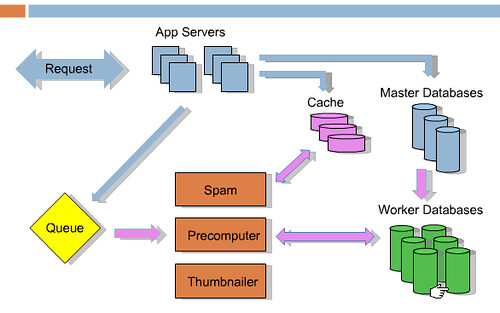
青の線はリクエスト発生時に起こることを表している。誰かがリンクを登録したり投票をすると,結果がキャッシュ,マスターデータベースとジョブのキューに行く。その後,ユーザに戻ってゆく。それ以外の処理はピンクの線で表されているようにオフラインで起こる。RedditではRabbitMQを使っている。