
簡易RSSリーダーを作る
 さて、いよいよリクエストとレスポンスを取り扱うための2つのクラスを活用し、RSSリーダーを作ってみましょう。
目標とするのは、フォームにRSSのURLを入力すると、RSSを読み込んで整形、タイトルやリンクなどを表示する簡易なものです。フォームの表示、RSSの整形表示も1つのスクリプトで行うようにします。また、読み込む対象とするのはRSS 2.0のみとします。RSSにはさまざまな規格があり、方言も多いため、手軽に扱えて方言の少ないRSSのみを扱うものとします。また、エンコードに関する処理を最小限度に抑えるため、RSSのエンコードは ASCIIとUTF-8のみに限定します。
RSSを読み込む
RSSを読み込み、Pythonで処理をするためには2つの処理が必要です。まず、Webの通信を通してRSSを文字列として取り込む必要があります。その後、読み込んだRSSを要素に分解してPythonのオブジェクトに変換します。
RSSをWebから読み込むためには、標準モジュールのurllibモジュールを使えばよいでしょう。読み込んだRSSは、XMLと呼ばれる構造を持った文字列となります。XMLを取り扱うためには、ElementTreeというモジュールを使うと便利です。ElementTreeはPython 2.5から標準モジュールとしてPythonに組み込まれていますので、別途インストールする必要もありません。
RSSを読み込み、辞書のリストとして要素を取り出すための関数を定義します。この関数は別のWebアプリケーションで利用することがあるかもしれません。関数を「rssparser.py」という名前のスクリプトファイルに書き出し、外部のプログラムからモジュールを通して利用できるようにします。
以下がモジュールの定義です。
rssparser.py
:::python
#!/usr/bin/env python # coding: utf-8
from xml.etree.ElementTree import ElementTree
from urllib import urlopen
def parse_rss(url):
"""
RSS 2.0をパースして、辞書のリストを返す
"""
rss=ElementTree(file=urlopen(url))
root=rss.getroot()
rsslist=[]
# RSS 2.0のitemエレメントだけを抜き出す
for item in [ x for x in root.getiterator()
if "item" in x.tag]:
rssdict={}
for elem in item.getiterator():
for k in ['link', 'title', 'description',
'author', 'pubDate']:
if k in elem.tag:
rssdict[k]=elem.text
else:
rssdict[k]=rssdict.get(k, "N/A")
rsslist.append(rssdict)
return rsslist
RSS 2.0では、ブログ記事などのタイトル、リンクなどの要素がitemというエレメントの中に収まっています。このスクリプトでは、RSS 2.0相当のXML文字列を先頭から読み込み、itemエレメントを探し出す、という処理をしています。itemエレメントを探し出したら、リンクやタイトルといった要素を辞書に登録します。
1つの記事に対する要素が1つの辞書になります。複数itemエレメントがある場合は、複数の辞書がリストに登録されます。関数の戻り値となるのは、itemエレメントの内容を収めた辞書のリストです。
Webアプリケーションを作る
リクエスト、レスポンスをスマートに扱うためのクラスを作りました。また、RSS 2.0を読み込み、Pythonのオブジェクトに変換するモジュールを作りました。いままで作ってきたものを組み合わせて、Webアプリケーションの本体となるスクリプトを作りましょう。ファイル名は「rssreader1.py」とします。httphandler.py、rssparser.pyとともに、cgi-binフォルダに設置します。PythonのWebサーバを立ち上げて、Webブラウザで/cgi-bin/rssreader1.pyというURLにアクセスすることでWebアプリケーションを利用できます。
図01 RSSリーダーの実行画面
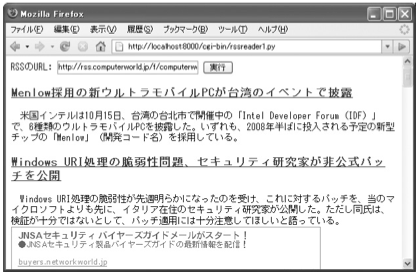
以下がWebアプリケーション用のプログラムです。これまでのサンプルプログラムは文字列の固まりというたたずまいでした。このプログラムではリクエストやレスポンスの扱いを工夫していることもあり、プログラムらしく見えると思います。
rssreader1.py
:::python
#!/usr/bin/env python
# coding: utf-8
from rssparser import parse_rss
from httphandler import Request, Response, get_htmltemplate
import cgitb; cgitb.enable() # (1)
form_body=u"""
<form method="POST" action="/cgi-bin/rssreader1.py">
RSSのURL:
<input type="text" size="40" name="url" value="%s"/>
<input type="submit" />
</form>"""
rss_parts=u"""
<h3><a href="%(link)s">%(title)s</a></h3>
<p>%(description)s</p>
""" # (3)
content=u"URLを入力してください"
req=Request() # (2)
if req.form.has_key('url'):
try:
rss_list=parse_rss(req.form['url'].value)
content=""
for d in rss_list:
content+=rss_parts%d
except:
pass
res=Response() # (4)
body=form_body%req.form.getvalue('url', '')
body+=content
res.set_body(get_htmltemplate()%body)
print res # (5)
プログラムの冒頭では、処理に利用するモジュールなどをインポートしています。インポートブロックの最後の行でcgitbというモジュールをインポートしています。このモジュールは、Webアプリケーションでエラーが起こったとき、分かりやすいエラーを表示するためのモジュールです。モジュールをインポートし、cgitb.enable()という関数を呼ぶと、エラーが起こったときにエラーの位置などを色つきで表示します(1)。
モジュール定義の後は、レスポンスとして出力する文字列を定義しています。form_bodyという変数にはRSSのURLを入力するフォームを表示するためのHTMLを定義しています。rss_partsには、RSSを整形表示するための文字列を定義しています。表示すべき要素が複数ある場合には、この文字列に必要な要素を埋め込み、繰り返し利用します。
後半以降はRSSを整形表示するための処理を行っています。まず、フォームに入力されたRSSのURLを取得するために、Requestクラスのインスタンスオブジェクトを作っています(2)。
「url」というキーがあった場合には、先ほど作った関数を使ってRSSをPythonのオブジェクトに変換します。変換したオブジェクトを元に、表示用のHTML文字列を作って足していきます。
rss_partsという変数に入った文字列は、RSSの要素を埋め込むテンプレートのような役割をしています。文字列の埋め込みにはフォーマット文字列機能を使っています。テンプレートには「%(link)s」のように辞書のキーが埋め込まれています(3)。テンプレートと辞書を組み合わせると、キーを元に置換を行います。
表示するHTMLができ上がったら、Responseクラスのインスタンスオブジェクトを作ります(4)。メソッドを使ってレスポンス本文をインスタンスに設定します。
最後に、Responseクラスのインスタンスを文字列として扱いprint文で表示します(5)。こうすると、Responseクラスに定義された__str__()メソッドが呼び出され、ヘッダを含めたレスポンス文字列全体がレスポンスとして送り出されます。これまでのサンプルでは、ヘッダを含めてprint文で表示していました。それに比べると、プログラムの書き方がずっとスマートになっているのが分かると思います。
Webアプリケーション開発とヒアドキュメント
これまで見てきたように、Webアプリケーションでは多くの文字列処理を行います。HTMLやレスポンスとして送信するヘッダのような文字列を扱うプログラムの内部に書くときには注意が必要です。プログラム自体も文字列なので、プログラムの内部にさまざまな種類の文字列が散らばってしまうと、プログラムが見づらくなってしまいます。また、プログラムのいろいろな場所に文字列が散らばっているのでは、プログラムの修正が難しくなってしまいます。
事実、このような問題はWebアプリケーションが登場した初期にはよく起こっていました。HTMLのような文字列とプログラムが混在したプログラムが多く書かれていました。プログラムを修正したり拡張するとき、開発者はまずどの部分がプログラムで、どの部分がレスポンスに使う文字列かを探り出す必要がありました。機能追加や修正が容易に行えないのでは、大規模なWebアプリケーションを作ることは難しくなってきます。このような手法はヒアドキュメントなどと呼ばれ、Webアプリケーションの開発では禁じ手とさ れています。 読みやすく、拡張や修正がしやすいWebアプリケーションを書くためには、文字列をプログラムに埋め込む方法に工夫が必要です。たとえば、繰り返し使う文字列は1箇所にまとめる。文字列の定義とプログラムを分ける。このような工夫をすることで、Webアプリケーションのプログラムはずっと見やすく、修正がしやすくなります。
このような工夫をすることが、効率的にWebアプリケーションを開発するための第一歩と言えます。最近では、より進んだ考え方や手法を活用して、もっと効率的にWebアプリケーションを開発する手法が利用されています。どのような手法があるのかについては、のちほど解説します。